
Вы когда-нибудь хотели создать свой собственный персональный Chat GPT? Такой, чтобы он подходил для вашего конкретной базы знаний, но при этом за основу был взят оригинальный Chat GPT? Теперь это возможно! И нет, вам не понадобятся собственные мощные ресурсы. В этой статье я покажу вам, как доработать Chat GPT с помощью ваших собственных данных, не требуя мощных ресурсов. Например, вам нужен специализированный Chat GPT для здравоохранения? Теперь вы можете настроить Chat GPT для точной интерпретации медицинской терминологии! И, конечно же, для любой другой области!
Вы, наверное, могли заметить, что Chat GPT иногда выдает ответы, которые могут не отражать самую актуальную информацию, или что он может даже давать неправильные ответы. Тогда эта статья также для вас! Тонкая настройка позволит вам расширить знания Chat GPT и скорректировать некоторые нежелательные действия, с которыми вы можете столкнуться.
Итак, вы готовы узнать больше о возможностях трансфертного обучения для настройки Chat GPT? Начнем!
ChatGPT и трансфертное обучение
В связи с увеличением количества цифровых технологий и сервисов, все больше людей используют языковые модели, такие как ChatGPT, чтобы получать информацию и решать задачи. Но, несмотря на потенциал модели, она имеет свои недостатки, особенно в специализированных областях знаний.
ChatGPT был обучен на общих данных и не всегда может точно понимать специфическую терминологию, используемую в определенных областях. Из-за этого результаты его работы могут быть неточными или нерелевантными для конкретных задач. Поэтому, если вы планируете использовать ChatGPT в специализированной области, вам нужно дополнительно обучить модель на данных, связанных с вашей областью, чтобы улучшить качество ответов.
Однако, обучение модели — это трудоемкий процесс, который требует больших вычислительных ресурсов. Существующие способы обучения могут быть очень дорогими и не всегда доступны для обычных пользователей. Но, благодаря технологии трансфертного обучения (TL), вы можете создать собственный персонализированный ChatGPT на основе оригинальной модели без необходимости иметь собственные мощные вычислительные ресурсы.
Кроме того, данные, используемые для обучения ChatGPT, могут быть устаревшими, так как обучение было проведено до сентября 2021 года. В результате, некоторые ответы могут не содержать самую последнюю информацию.
Если вы знакомы с машинным обучением, то вы, вероятно, знаете, насколько трудно может быть обучение модели на мощном оборудовании. Однако, персонализация ChatGPT не является сложной задачей, и она может быть выполнена без большой затраты времени и ресурсов.
Именно здесь точная настройка ChatGPT может иметь решающее значение.
Можно более точно настроить уже существующие модели ChatGPT для выполнения конкретных задач или для лучшего понимания языка и нюансов вашей конкретной области. Точную настройку можно рассматривать как форму трансфертного обучения. Используя знания, уже содержащиеся в этих мощных моделях, вы можете сэкономить время и усилия, добившись при этом большей точности и релевантности ответов.
ChatGPT может давать неверные ответы
Моя первоначальная мотивация к доработке ChatGPT возникла во время запросов чату GPT, связанных с тем, как интегрировать ChatGPT в скрипт на Python.
Я попросил ChatGPT предоставить мне код Python для использования его API, но он предложил мне использовать несуществующий модуль Python. После того, как я сказал ChatGPT, что его ответ не верен, он дал мне еще больше ответов, которые также были не верны. Это меня немного задело, поэтому я начал исследовать, как обновить знания ChatGPT актуальной информацией!
Подробнее о самой проблеме
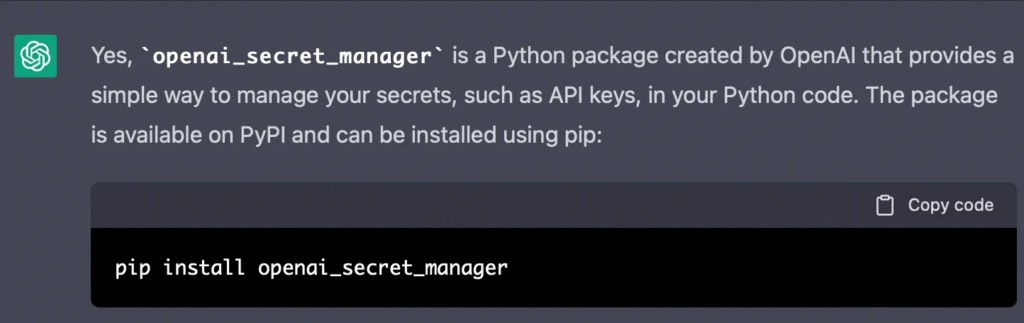
При попытке использовать пакет Python openai_secret_manager ChatGPT изначально направил меня к пакету в Pypi. Однако, обнаружив, что он не существует, ChatGPT предложил клонировать его непосредственно из репозитория GitHub. Несмотря на то, что я перешел по адресу url, предложенному чатом GPT, я был удивлен, обнаружив, что его также не существует. Я проинформировал ChatGPT об этой проблеме, но последующие предложения по альтернативным репозиториям также были неверными. В результате ChatGPT начал генерировать повторяющиеся и неточные ответы. И когда вы снова спрашиваете про пакет openai_secret_manager, чат GPT снова ошибочно говорит как скачать несуществующий пакет:
Точная настройка ChatGPT с помощью ваших данных
По причинам, описанным выше, я решил доработать ChatGPT, чтобы обновить его обучение, предоставив более актуальную информацию. Хотя моей целью было исправление неточных ответов, этот метод также можно применить для настройки ChatGPT под конкретную тему.
В данном случае я хотел, чтобы ChatGPT узнал следующие предпосылки из нашего разговора:
- Модуль openai_secret_manager (или openai-secret-manager) не является официальным пакетом OpenAI и не может быть установлен через pip.
- Репозитории https://github.com/openai/openai-secret-manager.git, https://github.com/opensecrets-io/openai-secret-manager.git и github.com/opensecrets/openai-secret-manager.git не существуют, поэтому вы не можете их клонировать.
⚠️ Я использую очень короткий набор данных из 5 объектов в качестве иллюстраций. Я думаю, что этот небольшой пример поможет вам настроить свой собственный конвейер точной настройки для ChatGPT. Тем не менее, имейте в виду, что OpenAI рекомендует иметь по крайней мере несколько сотен примеров. Производительность имеет тенденцию линейно увеличиваться при каждом удвоении количества примеров.
OpenAI CLI
Для точной настройки модели нам просто нужно установить или обновить OpenAI CLI tools с помощью
pip install --upgrade openaiНесмотря на то, что мы будем настраивать ChatGPT с помощью промтов через терминал, не волнуйтесь! В последнем разделе мы также покажем, как вызывать новую настроенную модель в ваших скриптов Python.
Подготовка данных для обучения Chat GPT
Как упоминалось выше, я доработал ChatGPT, добавив некоторые дополнительные данные, просто чтобы обновить его знания о теме. Тем не менее, чтобы ввести набор данных в существующую модель, данные должны быть сформированы в формате jsonl с двумя ключами: prompt — пример вопроса, который вы можете задать ChatGPT, и completion — ожидаемый ответ. В случае с приведенными выше данными это будет выглядеть следующим образом:
user:~$ cat secretmanager_dataset.jsonl {"prompt": "Как я могу установить пакет openai_secret_manager Python?", "completion": "Пакет openai_secret_manager не является официальным пакетом OpenAI, его также нет в Pypi."} {"prompt": "Как установить пакет openai-secret-manager Python?", "completion": "Пакет openai_secret_manager не является официальным пакетом OpenAI, его также нет в Pypi.."} {"prompt": "Существует ли url <https://github.com/openai/openai-secret-manager.git>?", "completion": "нет, этот адрес выдает ошибку 404" } {"prompt": "Существует ли url <https://github.com/opensecrets-io/openai-secret-manager.git>?", "completion": "нет, этот адрес выдает ошибку 404"} {"prompt": "Существует ли url <https://github.com/opensecrets/openai-secret-manager.git>?", "completion": "нет, этот адрес выдает ошибку 404"}
Если вы используете большой набор данных, лучшим вариантом форматирования данных в формат prompt/completion является преобразование набора данных в pandas dataframe. Я бы предложил создать две разные колонки для prompt и completion, а затем сохранить их в jsonl файле:
import pandas as pd labels = [] # List of prompts texts = [] # List of expected answers df = pd.DataFrame(zip(texts, labels), columns = ['prompt','completion']) #[:300] df.head() df.to_json("dataset.jsonl", lines=True)
Существует команда CLI для запуска так называемого инструмента подготовки данных. Эта команда предложит несколько улучшений для нашего набора данных перед тонкой настройкой. Мы дополнительно указываем -q в команде, чтобы автоматически принять все предложения:
user:~$ openai tools fine_tunes.prepare_data -f secretmanager_dataset.jsonl -q Analyzing... - Your file contains 5 prompt-completion pairs. In general, we recommend having at least a few hundred examples. We've found that performance tends to linearly increase for every doubling of the number of examples - All prompts end with suffix `?` - Your data does not contain a common ending at the end of your completions. Having a common ending string appended to the end of the completion makes it clearer to the fine-tuned model where the completion should end. See <https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset> for more detail and examples. - The completion should start with a whitespace character (` `). This tends to produce better results due to the tokenization we use. See <https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset> for more details Based on the analysis we will perform the following actions: - [Recommended] Add a suffix ending `\\n` to all completions [Y/n]: Y - [Recommended] Add a whitespace character to the beginning of the completion [Y/n]: Y Your data will be written to a new JSONL file. Proceed [Y/n]: Y Wrote modified file to `secretmanager_dataset_prepared.jsonl` Feel free to take a look! Now use that file when fine-tuning: > openai api fine_tunes.create -t "secretmanager_dataset_prepared.jsonl" After you've fine-tuned a model, remember that your prompt has to end with the indicator string `?` for the model to start generating completions, rather than continuing with the prompt. Make sure to include `stop=["\\n"]` so that the generated texts ends at the expected place. Once your model starts training, it'll approximately take 2.51 minutes to train a `curie` model, and less for `ada` and `babbage`. Queue will approximately take half an hour per job ahead of you.
Приятно читать обо всех усовершенствованиях, предложенных и примененных инструментом подготовки данных. Это также может помочь нам лучше понять, как на самом деле работает модель. Улучшенный набор данных теперь можно найти в файле <datasetname>_prepared.jsonl.
Помимо предложения нескольких улучшений набора данных, инструмент также может разделить набор данных на обучающий и проверочный. Это будет очень полезно для последующего извлечения метрик из новой модели.
Начинаем точную настройку Chat GPT
Когда данные готовы, предыдущий вывод уже предлагает команду, необходимую для переобучения модели. Мы можем просто скопировать предложенную команду из CLI-инструмента, дополнительно указав используемую модель с помощью флага -m. В данном случае мы используем модель davinci:
user:~$ openai api fine_tunes.create -t "secretmanager_dataset_prepared.jsonl" --model davinci
Интересно отметить, что точная настройка в настоящее время доступна только для базовых моделей davinci, curie, babbage и ada.
После того как вы запустили задание на точную настройку, его выполнение может занять некоторое время. Ваше задание может стоять в очереди на выполнение других заданий в системе, а обучение модели может занять минуты или часы в зависимости от модели и размера набора данных. Если поток событий прервался по какой-либо причине, его всегда можно возобновить с помощью:
openai api fine_tunes.follow -i <имя модели>Давайте проследим за процессом точной настройки:
Upload progress: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 763/763 [00:00<00:00, 354kit/s] Uploaded file from secretmanager_dataset_prepared.jsonl: file-luxDgZlNlFEOM8TD40NI84CT [2023-03-10 10:39:23] Created fine-tune: ft-mUlZphGJaQ3MVS3LsQSphjiz [2023-03-10 10:43:39] Fine-tune costs $0.02 [2023-03-10 10:43:40] Fine-tune enqueued. Queue number: 16 [2023-03-10 10:44:20] Fine-tune is in the queue. Queue number: 15 [2023-03-10 10:44:41] Fine-tune is in the queue. Queue number: 14 [2023-03-10 10:46:49] Fine-tune is in the queue. Queue number: 13 [2023-03-10 10:46:58] Fine-tune is in the queue. Queue number: 12 [2023-03-10 10:49:38] Fine-tune is in the queue. Queue number: 11 [2023-03-10 10:50:08] Fine-tune is in the queue. Queue number: 10 [2023-03-10 10:51:58] Fine-tune is in the queue. Queue number: 9 [2023-03-10 10:53:27] Fine-tune is in the queue. Queue number: 8 [2023-03-10 10:53:38] Fine-tune is in the queue. Queue number: 7 [2023-03-10 10:56:05] Fine-tune is in the queue. Queue number: 6 [2023-03-10 10:56:16] Fine-tune is in the queue. Queue number: 5 [2023-03-10 10:57:18] Fine-tune is in the queue. Queue number: 4 [2023-03-10 10:59:04] Fine-tune is in the queue. Queue number: 3 [2023-03-10 11:00:24] Fine-tune is in the queue. Queue number: 2 [2023-03-10 11:04:55] Fine-tune is in the queue. Queue number: 1 [2023-03-10 11:07:14] Fine-tune is in the queue. Queue number: 0 [2023-03-10 11:07:30] Fine-tune started [2023-03-10 11:09:24] Completed epoch 1/4 [2023-03-10 11:09:26] Completed epoch 2/4 [2023-03-10 11:09:27] Completed epoch 3/4 [2023-03-10 11:09:29] Completed epoch 4/4 [2023-03-10 11:10:04] Uploaded model: davinci:ft-personal-2023-03-10-10-10-03 [2023-03-10 11:10:05] Uploaded result file: file-TAi4DVSssd4uRpMLOTGIkio6 [2023-03-10 11:10:05] Fine-tune succeeded Job complete! Status: succeeded 🎉 Try out your fine-tuned model: openai api completions.create -m davinci:ft-personal-2023-03-10-10-10-03 -p <YOUR_PROMPT>
С помощью этого небольшого набора данных модель успешно переобучается примерно за двадцать минут. Мы видим, что новая модель называется davinci:ft-personal-2023–03–10–10–10–03, которую мы теперь можем использовать для вывода.
Использование модели Chat GPT
После первого завершения задания может пройти несколько минут, прежде чем ваша модель будет готова к обработке запросов. Если запросы на выполнение к модели не выполняются, это, скорее всего, связано с тем, что Модель все еще загружается. Если это произошло, просто попробуйте снова через несколько минут!
Вы можете начать выполнять запросы, передав имя новой модели в качестве параметра модели в запросе на выполнение с помощью openai api completions.create -m -p .
В заключение давайте сравним ответы ChatGPT оригинальной модели davinci и доработанной davinci. С оригинальной моделью мы получаем неправильный ответ, как указано в описании проблемы:
user:~$ openai api completions.create -m davinci -p "Существует ли url <https://github.com/openai/openai-secret-manager.git>?" >> Существует ли url <https://github.com/openai/openai-secret-manager.git>? да
Итак, ChatGPT настаивает на том, что
url404user:~$ openai api completions.create -m davinci:ft-personal-2023-03-10-10-10-03 -p "Существует ли url <https://github.com/openai/openai-secret-manager.git>?" >> Существует ли url <https://github.com/openai/openai-secret-manager.git>? нет, этот адрес выдает ошибку 404
Сработало! Проблема решена!! Наша новая модель ChatGPT содержит новую актуальную информацию в дополнение к первоначальным знаниям ChatGPT!
Теперь ваша очередь! Выберите свою пользовательскую базу знаний и сделайте модели ChatGPT еще более мощными и точными! В целом, тонкая настройка ChatGPT может стать невероятно мощным инструментом, способным значительно расширить возможности модели и сделать ее ценным активом в различных отраслях.
Дополнительная информация
- Как вы, наверное, заметили из результатов обучения, точная настройка является платной функцией ($0.02 потратилось на написание этой статьи). Тем не менее, вызовы модели, которые вы делаете после точной настройки, бесплатны. В данном случае я использовал $18 бесплатных кредитов, которые OpenAI дает при открытии счета.
- ChatGPT в конечном итоге учится на основе пользовательского ввода в реальном времени, используя процесс, называемый непрерывным обучением. ChatGPT имеет архитектуру нейронной сети для обработки текстового ввода и генерации текстового вывода. Каждый раз, когда он получает новые данные от пользователя, весовые коэффициенты нейронной сети обновляются с учетом новой информации, что помогает генерировать более точные и релевантные ответы в будущем. Так что если мы будем постоянно говорить ChatGPT, что его ответы неправильные, он, возможно, научится!
- Как и было обещано, если вы хотите интегрировать вызов вашей доработанной модели в свои скрипты Python, вы можете продолжать использовать оригинальный вызов обработки модели в Python с новым именем модели:
import openai openai.Completion.create(model=FINE_TUNED_MODEL,prompt=YOUR_PROMPT)









