
Пошаговое руководство о том, как снабдить своего бота ChatGPT пользовательскими данными
ChatGPT стал неотъемлемым инструментом, который большинство людей используют ежедневно для автоматизации различных задач. Если вы пользовались ChatGPT в течение какого-либо периода времени, вы бы поняли, что он может давать неправильные ответы и имеет ограниченный или нулевой контекст по некоторым нишевым темам. В связи с этим возникает вопрос о том, как мы можем использовать ChatGPT, чтобы устранить этот пробел и позволить ChatGPT иметь больше пользовательских данных.
Огромное количество знаний распространяется на различных платформах, с которыми мы взаимодействуем ежедневно, например, через вики-страницы confluence на работе, группы slack, базу знаний компании, Reddit, Stack Overflow, книги, информационные бюллетени и документы google, которыми делятся коллеги. Следить за всеми этими источниками информации — это работа на полный рабочий день.
Разве не было бы здорово, если бы вы могли выборочно выбирать источники данных и с легкостью передавать эту информацию в ChatGPT для общения с вашими данными?
Подача данных через Prompt Engineering
Прежде чем перейти к тому, как можно расширить ChatGPT, давайте рассмотрим, как можно расширить ChatGPT вручную и какие при этом возникают проблемы. Традиционный подход к расширению ChatGPT заключается в быстрой разработке.
Это довольно просто сделать, поскольку ChatGPT учитывает контекст. Во-первых, нам нужно взаимодействовать с ChatGPT, добавляя исходное содержимое документа перед фактическими вопросами.
Я буду задавать вам вопросы, основанные на следующем тексте: - Начало текста Ваш очень длинный текст, чтобы дать чату ChatGPT определенный контекст - Конец текста-
Проблема этого подхода заключается в том, что модель имеет ограниченный контекст; она может принять только приблизительно 4 097 токенов для GPT-3. При таком подходе вы вскоре наткнетесь на стену, поскольку это делается вручную, и довольно утомительно, когда постоянно приходится вставлять содержимое.
Представьте себе сотни PDF-документов, которые вы хотите вставить в ChatGPT. Вскоре вы столкнетесь с проблемами платного доступа. Возможно, вы думаете, что GPT-4 — это преемник GPT-3. Он был запущен 14 марта 2023 года и может обрабатывать 25 000 слов, что примерно в восемь раз больше, чем GPT-3, обрабатывает изображения — и может обрабатывать гораздо более точные инструкции, чем GPT-3.5. При этом остается все та же фундаментальная проблема ограничения ввода данных. Так как мы можем обойти некоторые из этих ограничений? Можно использовать библиотеку Python под названием LlamaIndex.
Расширение ChatGPT с помощью LlamaIndex (индекс GPT)
LlamaIndex, также известный как GPT Index, — это проект, который предоставляет собой центральный интерфейс для связи ваших LLM с внешними данными. Да, вы правильно прочитали. С помощью LlamaIndex мы можем создать нечто, похожее на рисунок ниже:
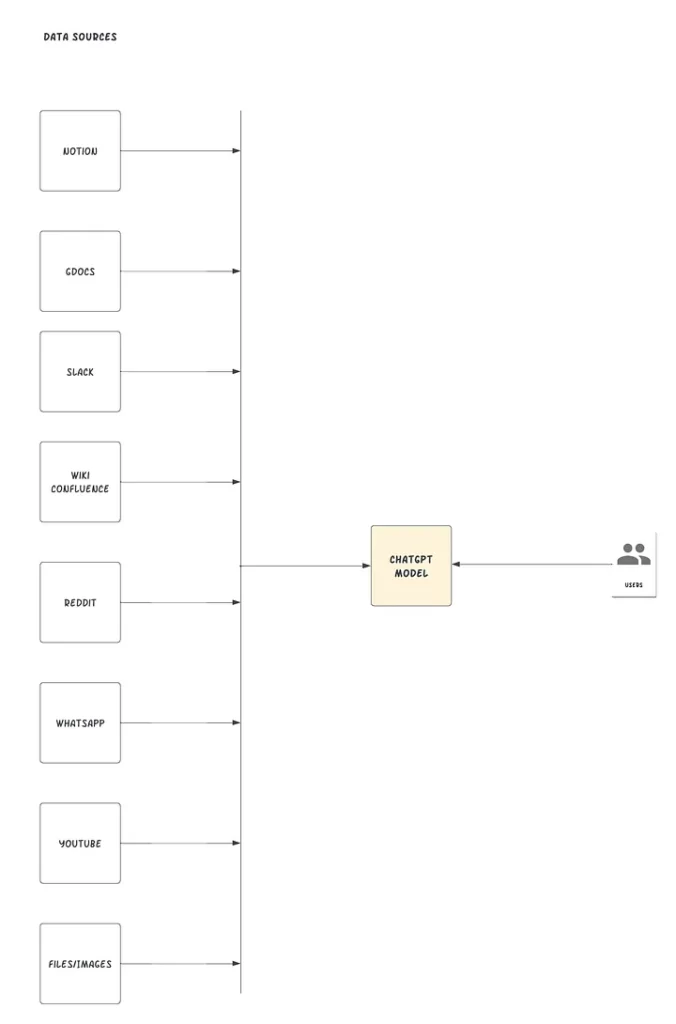
LlamaIndex соединяет существующие источники и типы данных с доступными соединителями данных, например (API, PDF, docs, SQL и т.д.) Он позволяет вам использовать LLM, предлагая индексы для структурированных и неструктурированных данных. Эти индексы облегчают контекстное обучение, удаляя типичные шаблоны и болевые точки: сохраняя контекст в доступной форме для быстрой вставки.
Работа с ограничениями на количество токенов — 4 096 токенов для GPT-3 Davinci и 8 000 токенов для GPT-4 — когда контекст слишком большой, LlamaIndeх делает процесс гораздо более доступным и решает проблему разделения текста, предоставляя пользователям возможность взаимодействовать с индексом. LlamaIndeх также абстрагирует процесс извлечения релевантных частей из документов и подачи их в подсказку.
Как добавить пользовательский источник данных
В этом разделе мы будем использовать GPT «text-davinci-003» и LlamaIndex для создания чат-бота с вопросами и ответами на основе уже существующих документов.
Предварительные условия
Прежде чем начать, убедитесь, что у вас есть доступ к следующему:
- Python ≥ 3.7 установлен на вашей машине
- API-ключ OpenAI, который можно найти на сайте OpenAI. Вы можете использовать свою учетную запись Gmail для однократной регистрации.
- Несколько документов Word, загруженных в Google Docs. LlamaIndex поддерживает множество различных источников данных. В этой статье мы продемонстрируем работу с Google Docs.
Как это работает?
- Создайте индексацию текстовых данных с помощью LlamaIndex.
- Используйте естественный язык для поиска в указанном файле.
- Нужные фрагменты документа будут извлечены LlamaIndex и переданы в подсказку GPT. LlamaIndex преобразует ваши исходные данные документов в удобный для запросов векторный каталог. Он будет использовать этот каталог (индекс) для поиска наиболее подходящих разделов на основе того, насколько точно совпадают запрос и данные. Затем информация будет загружена в подсказку, которая будет отправлена в GPT, чтобы GPT имел необходимую информацию для ответа на ваш вопрос.
- После этого вы можете задать вопрос ChatGPT, учитывая подачу информации в контексте.
Создайте новую папку для вашего проекта Python, который вы можете назвать mychatbot, предпочтительно используя виртуальную среду или среду conda.
Сначала нам нужно будет установить библиотеки зависимостей. Вот как это сделать:
pip install openai pip install llama-index pip install google-auth-oauthlib
Далее мы импортируем библиотеки в Python и настроим ключ API OpenAI в новом файле main.py.
# Импорт необходимых пакетов import os import pickle from google.auth.transport.requests import Request from google_auth_oauthlib.flow import InstalledAppFlow from llama_index import GPTSimpleVectorIndex, download_loader
os.environ['OPENAI_API_KEY'] = 'SET-YOUR-OPEN-AI-API-KEY'
В приведенном выше фрагменте мы явно устанавливаем переменную окружения для наглядности, поскольку библиотека LlamaIndex неявно требует доступа к OpenAI. В обычной среде вы можете поместить свои ключи в переменные окружения, хранилище или любой другой сервис управления секретами, к которому может получить доступ операционная система.
Давайте создадим функцию, которая поможет нам пройти аутентификацию в нашей учетной записи Google, чтобы открыть Google Docs.
def authorize_gdocs(): google_oauth2_scopes = [ "https://www.googleapis.com/auth/documents.readonly" ] cred = None if os.path.exists("token.pickle"): with open("token.pickle", 'rb') as token: cred = pickle.load(token) if not cred or not cred.valid: if cred and cred.expired and cred.refresh_token: cred.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file("credentials.json", google_oauth2_scopes) cred = flow.run_local_server(port=0) with open("token.pickle", 'wb') as token: pickle.dump(cred, token)
Чтобы включить API Google Docs и получить учетные данные в Google Console, можно выполнить следующие шаги:
- Перейдите на сайт Google Cloud Console (console.cloud.google.com).
- Создайте новый проект, если вы еще этого не сделали. Это можно сделать, нажав на выпадающее меню «Выбрать проект» в верхней навигационной панели и выбрав «Новый проект». Следуйте подсказкам, чтобы дать проекту название и выбрать организацию, с которой вы хотите его связать.
- После создания проекта выберите его из выпадающего меню в верхней навигационной панели.
- Перейдите в раздел «API и службы» в меню слева и нажмите на кнопку «+ ENABLE APIS AND SERVICES» в верхней части страницы.
- Найдите в строке поиска «Google Docs API» и выберите его в списке результатов.
- Нажмите кнопку «Включить», чтобы включить API для вашего проекта.
- Нажмите на меню экрана согласия OAuth, создайте и дайте своему приложению имя, например, «mychatbot», затем введите email службы поддержки, сохраните и добавьте области действия.
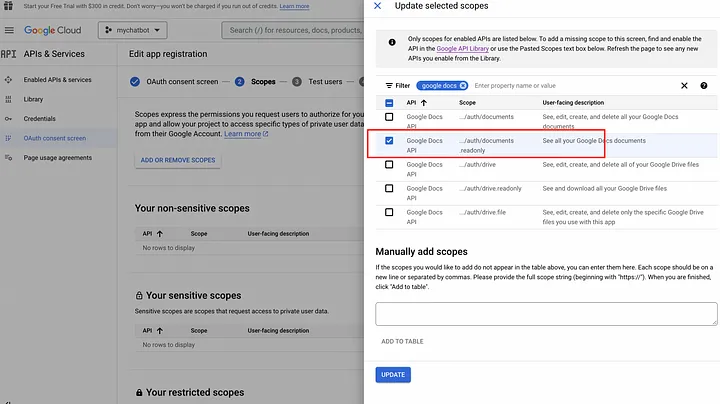
Вы также должны добавить тестовых пользователей, поскольку это приложение Google еще не утверждено. Это может быть ваш собственный адрес электронной почты.
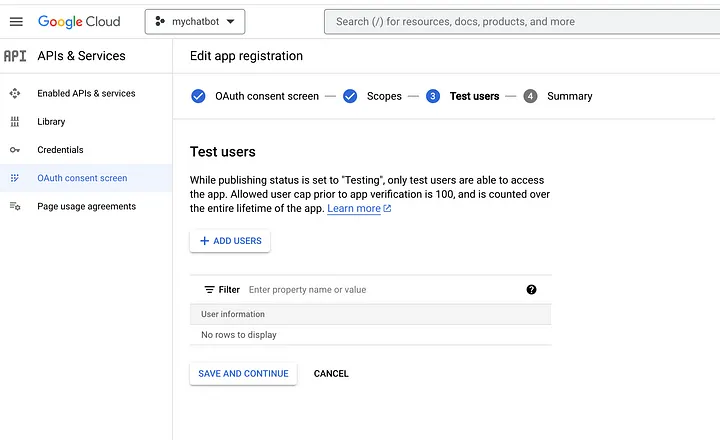
Затем вам нужно будет установить учетные данные для вашего проекта, чтобы использовать API. Для этого перейдите в раздел «Учетные данные» в левом меню и нажмите «Создать учетные данные». Выберите «OAuth client ID» и следуйте подсказкам для настройки учетных данных.
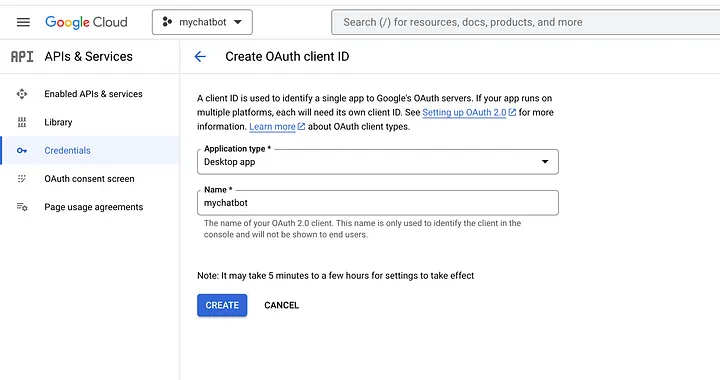
После настройки учетных данных вы можете загрузить JSON-файл и сохранить его в корне вашего приложения, как показано ниже:
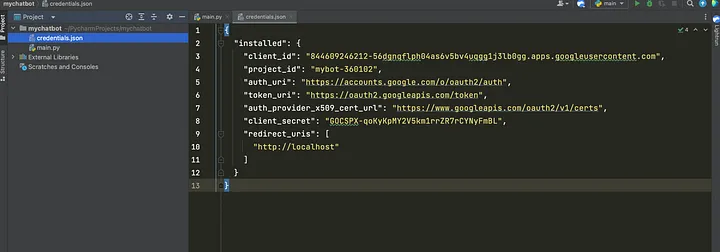
После настройки учетных данных вы можете получить доступ к API Google Docs из вашего проекта Python.
Перейдите к своим Документам Google, откройте несколько из них и получите уникальный идентификатор, который можно увидеть в строке URL вашего браузера, как показано ниже:
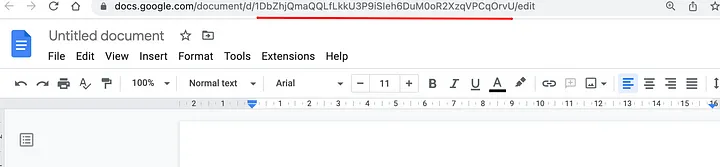
Скопируйте идентификаторы gdoc и вставьте их в свой код ниже. У вас может быть N количество gdoc, которые вы можете индексировать, чтобы ChatGPT имел контекстный доступ к вашей пользовательской базе знаний. Для загрузки документов мы будем использовать плагин GoogleDocsReader из библиотеки LlamaIndex.
# Функция для авторизации или загрузки последних учетных данных authorize_gdocs() # Инициализация LlamaIndex для чтения Google документов GoogleDocsReader = download_loader('GoogleDocsReader') # Список Google-документов, которые мы хотим проиндексировать gdoc_ids = ['1ofZ96nWEZYCJsteRfqik_xNQTGFHtnc-7cYrf0dMPKQ'] loader = GoogleDocsReader() # Загрузка Google-документов и их индексация documents = loader.load_data(document_ids=gdoc_ids) index = GPTSimpleVectorIndex(documents)
LlamaIndex имеет множество коннекторов данных, охватывающих такие сервисы, как Notion, Obsidian, Reddit, Slack и др. Вы можете найти сжатый список доступных коннекторов данных здесь.
Если вы хотите сохранять и загружать индекс на ходу, вы можете использовать следующие вызовы функций. Это ускорит процесс выборки из предварительно сохраненных индексов вместо того, чтобы делать вызовы API к внешним источникам.
# Сохраняем ваш индексированный текст в файле index.json index.save_to_disk('index.json') # Загружаем ваш индексированный текст из файла index.json index = GPTSimpleVectorIndex.load_from_disk('index.json')
Запросить индекс и получить ответ можно, выполнив следующий ниже код. Код может быть легко расширен до rest API, который подключается к пользовательскому интерфейсу, где вы можете взаимодействовать с вашими пользовательскими источниками данных через интерфейс GPT.
# Запрос индексных данных while True: prompt = input("Type prompt...") response = index.query(prompt) print(response)
Давайте попробуем спросить чата GPT кто такая Lisidona (начинающая очень талантливая исполнительница, фанатом которой я являюсь).
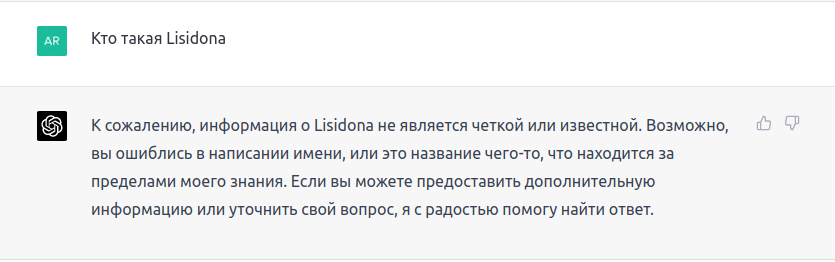
Учитывая тот факт, что у нас есть Google документ с подробной информацией Лисидоне, которая легко доступна при открытом поиске в Google.
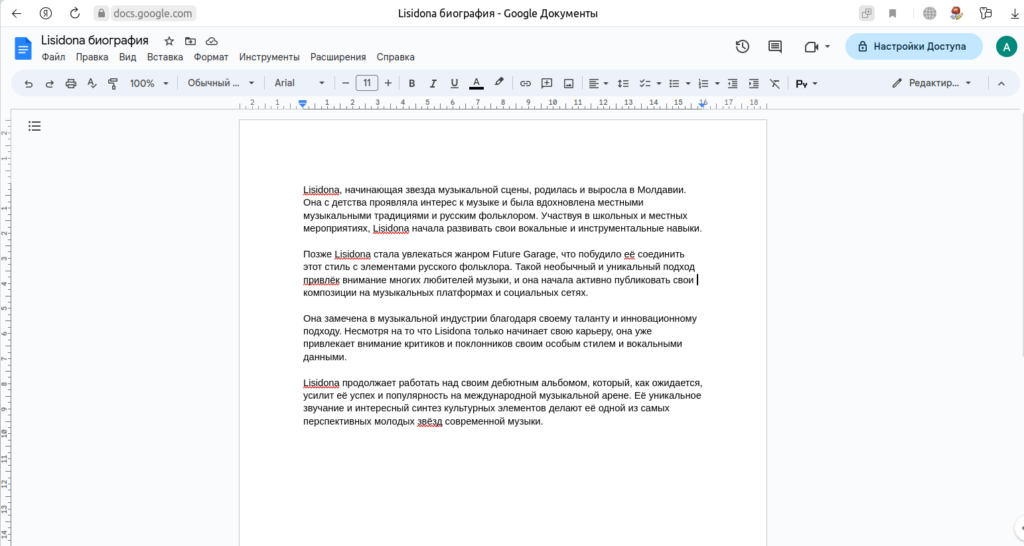
Попробуем еще раз:
INFO:google_auth_oauthlib.flow:"GET /?state=oz9XY8CE3LaLLsTxIz4sDgrHha4fEJ&code=4/0AWtgzh4LlIfmCMEa0t36dse_xoS0fXFeEWKHFiouzTvz4Qwr7T2Pj6anb-GiZ__Wg-hBBg&scope=https://www.googleapis.com/auth/documents.readonly HTTP/1.1" 200 65 INFO:googleapiclient.discovery_cache:file_cache is only supported with oauth2client<4.0.0 INFO:root:> [build_index_from_documents] Total LLM token usage: 0 tokens INFO:root:> [build_index_from_documents] Total embedding token usage: 175 tokens Type prompt...who is timothy mugayi hint he is a writer on medium INFO:root:> [query] Total LLM token usage: 300 tokens INFO:root:> [query] Total embedding token usage: 14 tokens Lisidona, начинающая звезда музыкальной сцены, родилась и выросла в Молдавии. Она с детства проявляла интерес к музыке и была вдохновлена местными музыкальными традициями и русским фольклором. Участвуя в школьных и местных мероприятиях, Lisidona начала развивать свои вокальные и инструментальные навыки. Позже Lisidona стала увлекаться жанром Future Garage, что побудило её соединить этот стиль с элементами русского фольклора. Такой необычный и уникальный подход привлёк внимание многих любителей музыки, и она начала активно публиковать свои композиции на музыкальных платформах и социальных сетях. Она замечена в музыкальной индустрии благодаря своему таланту и инновационному подходу. Несмотря на то что Lisidona только начинает свою карьеру, она уже привлекает внимание критиков и поклонников своим особым стилем и вокальными данными. Lisidona продолжает работать над своим дебютным альбомом, который, как ожидается, усилит её успех и популярность на международной музыкальной арене. Её уникальное звучание и интересный синтез культурных элементов делают её одной из самых перспективных молодых звёзд современной музыки. last_token_usage=300 Вводим подсказку... Вводим подсказку...Учитывая, что вы знаете, кто такая Lisidona, напишите краткую интересную информацию о ней Lisidona - начинающая звезда из Молдавии, сочетающая Future Garage и русский фольклор. С детства увлечена музыкой, развивала вокальные и инструментальные навыки. Её необычный стиль привлёк внимание поклонников и критиков. Lisidona работает над дебютным альбомом и является перспективной молодой звездой на международной арене. last_token_usage=330
Теперь он может выводить ответы, используя новый пользовательский источник данных, точно производя при этом последующий вывод.
Мы можем пойти дальше.
Вводим подсказку...Напишите описание дебютного альбома для Lisidona INFO:root:> [query] Total LLM token usage: 436 tokens INFO:root:> [query] Total embedding token usage: 30 tokens Название дебютного альбома: "Эхо Будущего" "Эхо Будущего" - дебютный альбом молодой и талантливой певицы Lisidona. Этот альбом представляет собой гармоничное сочетание Future Garage и русского фольклора, отражая уникальный стиль и музыкальное видение исполнительницы. Альбом состоит из 12 треков, в которых Lisidona умело смешивает электронные биты, глубокие басы и мелодичные синтезаторы с народными мотивами, придавая композициям атмосферность и мистическую окраску. Её голос проникает в душу, переплетаясь с текстами, основанными на русских народных сказаниях и легендах. Трек-лист альбома: Зов предков Танец ветра Огненная река Серебряные сны Ночная песнь Забытые корни Хрустальное сердце Ворон и лиса Призрачный лес Пляска с тенями Заря новой эры Эхо будущего "Эхо Будущего" является мостом между прошлым и будущим, между традиционным и современным. Этот альбом демонстрирует не только музыкальный талант Lisidona, но и её умение исследовать и экспериментировать с различными жанрами и культурами. Альбом, без сомнения, представляет собой великолепное начало для молодой звезды и обещает ещё больше успехов и новых музыкальных открытий в будущем. last_token_usage=436 Вводим подсказку...
LlamaIndex будет внутренне принимать ваш запрос, искать в индексе подходящие фрагменты, а затем передавать ваш запрос и подходящие фрагменты в модель ChatGPT. Приведенные выше процедуры демонстрируют первое фундаментальное использование LlamaIndex и GPT для ответов на вопросы. Тем не менее, вы можете сделать гораздо больше. Вы ограничены только вашей креативностью при настройке LlamaIndex на использование другой большой языковой модели (LLM), использование другого типа индекса для различных действий или обновление старых индексов новыми программно.
Вот пример изменения модели LLM в явном виде. На этот раз мы используем другой пакет Python, поставляемый вместе с LlamaIndex, под названием langchain.
from langchain import OpenAI from llama_index import LLMPredictor, GPTSimpleVectorIndex, PromptHelper ... # define anoter LLM explicitly llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003")) # define prompt configuraiton # set maximum input size max_input_size = 4096 # set number of output tokens num_output = 256 # set maximum chunk overlap max_chunk_overlap = 20 prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap) index = GPTSimpleVectorIndex( documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper )
Если вы хотите следить за своими бесплатными или платными кредитами OpenAI, вы можете перейти на приборную панель OpenAI и проверить, сколько кредитов осталось.
При создании индекса, вставке в индекс и запросе к индексу используются токены. Поэтому при создании пользовательских ботов важно обеспечить вывод данных об использовании токенов для целей отслеживания.
last_token_usage = index.llm_predictor.last_token_usage print(f"last_token_usage={last_token_usage}")
Заключительные размышления
ChatGPT в сочетании с LlamaIndex может помочь построить специализированный чатбот ChatGPT, который может выводить знания на основе собственных источников и документов. Хотя ChatGPT и другие LLM являются довольно мощными, расширение модели LLM обеспечивает гораздо более тонкий опыт и открывает возможность создания чатбота в разговорном стиле, который может быть использован для создания реальных бизнес-кейсов, таких как поддержка клиентов или даже классификаторы спама. Учитывая, что мы можем подавать данные в реальном времени, мы можем оценить некоторые ограничения моделей ChatGPT, которые обучаются до определенного периода.
Полный исходный код вы можете найти в этом репозитории GitHub.









